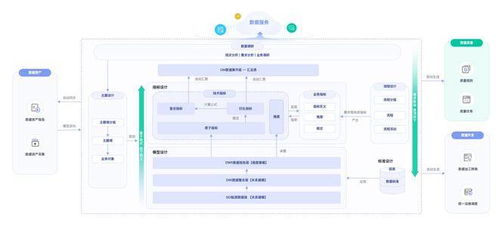
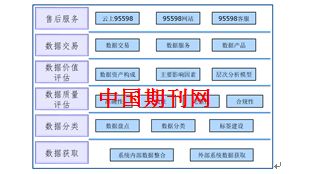
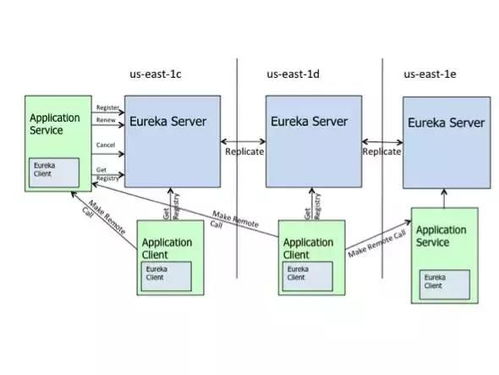
在微服務架構的演進過程中,數據治理已成為確保系統穩定性、可觀測性與業務連續性的核心挑戰之一。隨著服務數量的增長,數據分散、異構、一致性問題日益凸顯。本節將深入探討微服務數據治理的關鍵方案,并重點聚焦于數據處理服務的構建與實踐。
一、微服務數據治理的核心挑戰
- 數據孤島與一致性:每個微服務擁有獨立的數據庫,導致業務數據分散,跨服務事務與數據一致性難以保障。
- 數據異構與標準化:不同服務可能采用不同的數據格式、存儲引擎或協議,增加了集成與處理的復雜度。
- 數據質量與可靠性:數據在流轉中可能因網絡延遲、服務故障等出現丟失、重復或錯誤。
- 實時處理與歷史回溯需求:業務既需要低延遲的實時數據處理,又需支持歷史數據的查詢與分析。
二、數據處理服務的設計原則
為應對上述挑戰,數據處理服務應遵循以下設計原則:
- 松耦合與高內聚:數據處理邏輯應獨立于業務服務,通過事件驅動或API接口進行交互。
- 可擴展與容錯性:支持水平擴展,通過重試機制、死信隊列等確保數據不丟失。
- 標準化與兼容性:定義統一的數據格式(如Avro、Protobuf)和通信協議(如gRPC、Kafka),降低集成成本。
- 可觀測與可審計:集成日志追蹤、監控指標,實現數據處理全鏈路的可視化與故障排查。
三、關鍵架構模式與實踐
- 事件驅動架構(EDA):
- 通過消息中間件(如Apache Kafka、RocketMQ)實現服務間異步通信,將數據變更作為事件發布,由數據處理服務訂閱并處理。
- 優點:解耦服務依賴,支持最終一致性,提升系統吞吐量。
- CQRS(命令查詢職責分離)模式:
- 將數據寫入(命令)與讀取(查詢)分離,針對高頻查詢場景可構建獨立的讀模型(如Elasticsearch、ClickHouse),減輕主數據庫壓力。
- 數據處理服務負責同步寫模型到讀模型,確保數據實時性。
- 數據管道與流處理:
- 采用流處理框架(如Apache Flink、Spark Streaming)構建實時數據管道,支持數據的清洗、轉換、聚合與入庫。
- 示例場景:用戶行為日志實時分析、庫存變動實時監控。
- 數據版本與血緣追蹤:
- 為數據實體添加版本號或時間戳,結合元數據管理工具(如Apache Atlas)記錄數據來源、處理步驟與流向,便于溯源與合規審計。
四、實施案例:訂單數據處理服務
假設電商平臺中,訂單服務與庫存服務獨立部署,需確保下單時庫存數據的一致性:
- 事件發布:訂單服務創建訂單后,發布“訂單已創建”事件至Kafka。
- 事件處理:數據處理服務消費該事件,調用庫存服務API進行庫存扣減,并記錄處理結果。
- 異常處理:若庫存不足,數據處理服務發布“庫存扣減失敗”事件,觸發訂單狀態回滾與用戶通知。
- 數據同步:將訂單與庫存變動記錄同步至讀模型(如Elasticsearch),支持實時訂單查詢。
五、工具與技術棧推薦
- 消息中間件:Kafka(高吞吐)、RocketMQ(事務消息)。
- 流處理框架:Flink(低延遲復雜計算)、Kafka Streams(輕量級集成)。
- 數據存儲:MySQL(事務型)、MongoDB(文檔型)、Redis(緩存)、時序數據庫(如InfluxDB)。
- 監控與追蹤:Prometheus(指標收集)、Jaeger(分布式追蹤)、ELK(日志分析)。
六、
微服務數據治理的核心在于平衡數據自治與全局一致性。通過構建專業的數據處理服務,采用事件驅動、CQRS等模式,結合流處理與可觀測工具,能夠有效化解數據分散帶來的挑戰,為業務提供高效、可靠的數據支撐。在實踐中,需根據業務場景靈活選擇架構與技術,并持續迭代優化數據處理鏈路,以應對未來數據規模與復雜度的增長。